

GraphQL лише за кілька років став популярною альтернативою REST API. Сьогодні ця технологія використовується в багатьох мовах: від PHP і Java до Scala та Ruby.
У цій статті я розповім, як працює GraphQL на Python, а також розберу приклади використання GraphQL із бібліотекою Strawberry.
GraphQL – що це і для чого потрібно
GraphQL – це мова запитів та їхньої обробки. Завдяки відкритості коду та активності ком’юніті користувачів ця мова швидко поширилась у різних проєктах.
Авторами GraphQL є команда Facebook. Щоб зрозуміти, навіщо вони ще у 2012 році вирішили створити мову запитів, розглянемо одну з проблем відомого всім REST API.
Уявімо проєкт про управління бібліотекою, де треба зробити запит до бази даних задля отримання списку авторів, кожен із яких написав якусь кількість книг. І тут одразу виникає запитання: а як запросити ці книги? Якщо разом з автором повертати список усіх його книг, то крім сутностей авторів можуть з’явитися десятки й сотні сутностей книг. У результаті розмір відповіді зросте у рази. При цьому самі книги у такій кількості часто не потрібні. За деякими рекомендаціями побудови RESTful API так робити не вважається правильним, але це вже окрема філософія 😉.

Альтернативний варіант: надіслати відповідний запит за книгами кожного автора. Але з’являється інша проблема. Якщо книжки все ж будуть потрібні, то для кожного автора полетить безліч додаткових запитів. Це викликає підвищене навантаження на систему.
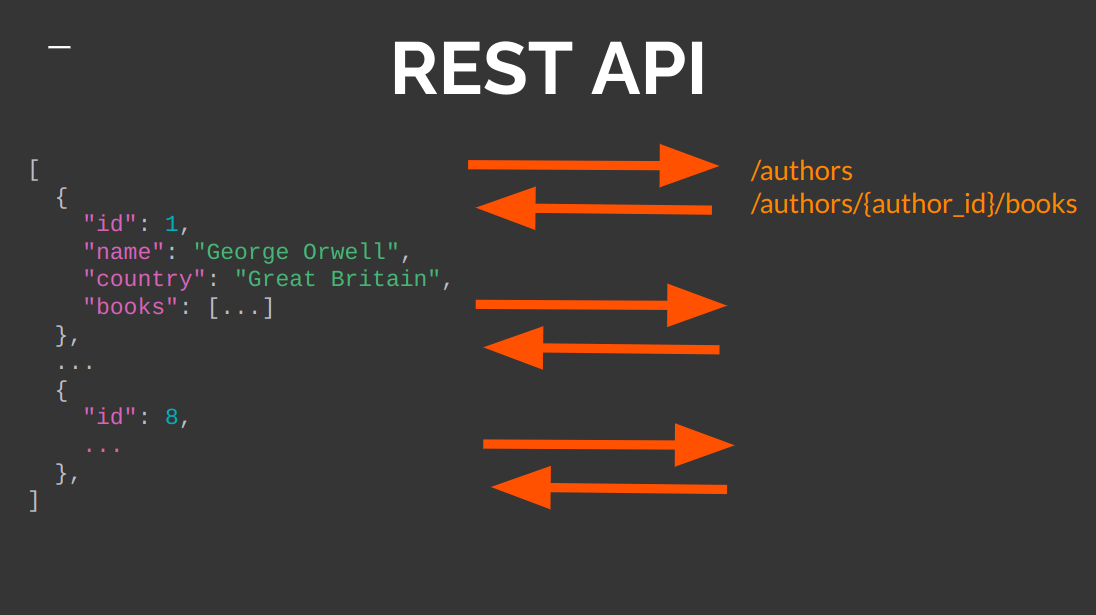
Ситуацію можна вирішити простіше. Наприклад, зробити ще один запит на книги із вказівкою, яким авторам потрібно повернути ці книги. Тобто буде лише два запити.
Але й тут не без проблем. Довжина URL не обмежена, але більшість браузерів не сприймає адреси довші за 2048 символів. Тобто кількість параметрів, яку ми можемо задати, обмежена довжиною строки.

Виникають питання з появою додаткових пов’язаних сутностей. Наприклад, якщо з’являться нагороди, то буде потрібно робити ще один запит.

Є й інший варіант. З огляду на рівні зрілості REST API, зокрема третій, разом із відповіддю повинно повертатися покликання, за якими можна отримати додаткові дані. Тобто отримаємо тільки те, що потрібно.
Виникне невеликий оверлоад у вигляді посилання, але це ні на що особливо не впливає. Якщо нам все ж будуть потрібні книги, то за вказаним URL можна отримати потрібні об’єкти.

Але й це вирішує не всі негаразди: проблема перебору вирішена, але недобору – ні. За потреби клієнту доведеться для кожного автора зробити безліч запитів на отримання багатьох книг.
REST як перевірений роками стандарт має інші механізми для розв’язання цих проблем. Чесно кажучи, всю логіку роботи GraphQL можна реалізувати поверх REST за допомогою тих самих query-параметрів. Наприклад, GET /authors?fields=books... Насправді все обмежується тільки фантазією і вашими силами, а GraphQL пропонує альтернативний підхід.
Схожі технології існують не тільки у Facebook. Наприклад, Netflix має свої рішення для подібних ситуацій, зокрема Falcor. Вони необхідні при оптимізації високонавантажених систем, де економія навіть половини респонсу скорочує витрати на хостинг на тисячі доларів.
Як працює GraphQL
GraphQL надає один ендпоінт. Він може називатися як завгодно, але найчастіше – /graphql. Вся логіка міститься у query. Це мова, якою можна скласти запит і вказати, який конкретно параметр необхідний. Якщо потрібні автори, вказуємо необхідні поля з моделі автора, наприклад, ID, ім’я. Якщо потрібні книги, то зазначаємо їх, а все зайве не вказуємо зовсім.

Ще одна перевага GraphQL – робота поверх звичного HTTP. Внаслідок цього можна використати будь-який зручний для вас клієнт. Потрібно додати до тіла запиту параметр query, куди передати Query як строку.

У відповідь ми отримуємо те, що запитували: ID, ім’я авторів, книги. Причому у нас надсилається лише один запит і надходить лише одна чітко структурована відповідь. У результаті автоматично вирішується проблема перебору та недобору даних, тисяч зайвих запитів і всього описаного вище.
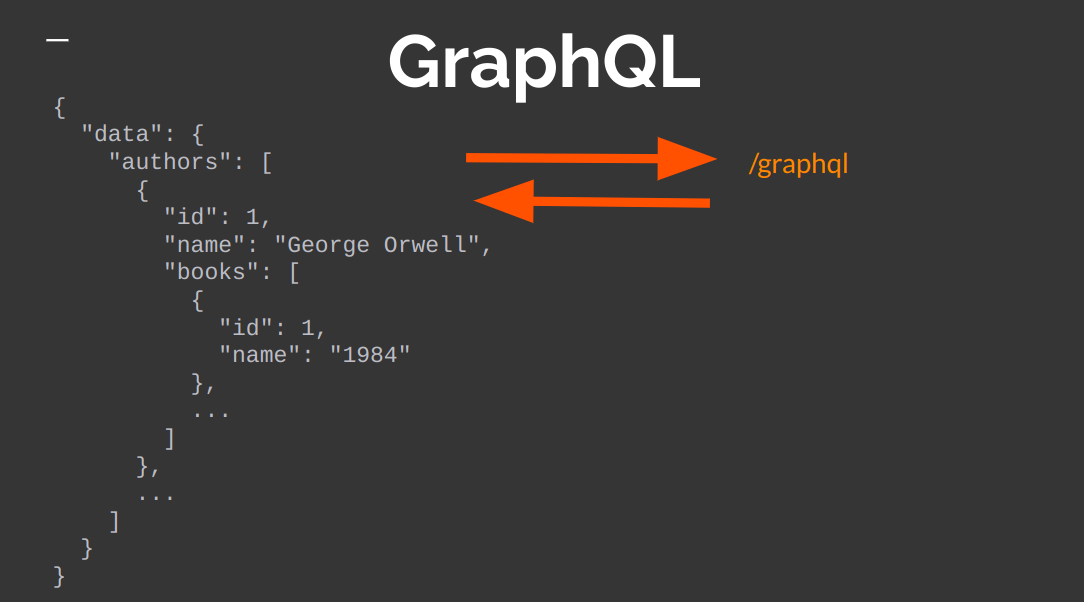
Як Python працює із GraphQL
Для роботи із GraphQL на Python існує багато бібліотек, але я зупинюся на Strawberry. При виборі я керувався насамперед асинхронністю й анотаціями типів. Якщо інші популярні бібліотеки досить зрілі й для типів використовують класи та методи класів, то Strawberry вміє інтерпретувати пітонівські типи у типи GraphQL. Сам же GraphQL визначає стрінги, інти, флоти, буліани тощо.

Достатньо вказати анотацію для типу Python, і бібліотека сама призведе до потрібного типу GraphQL.
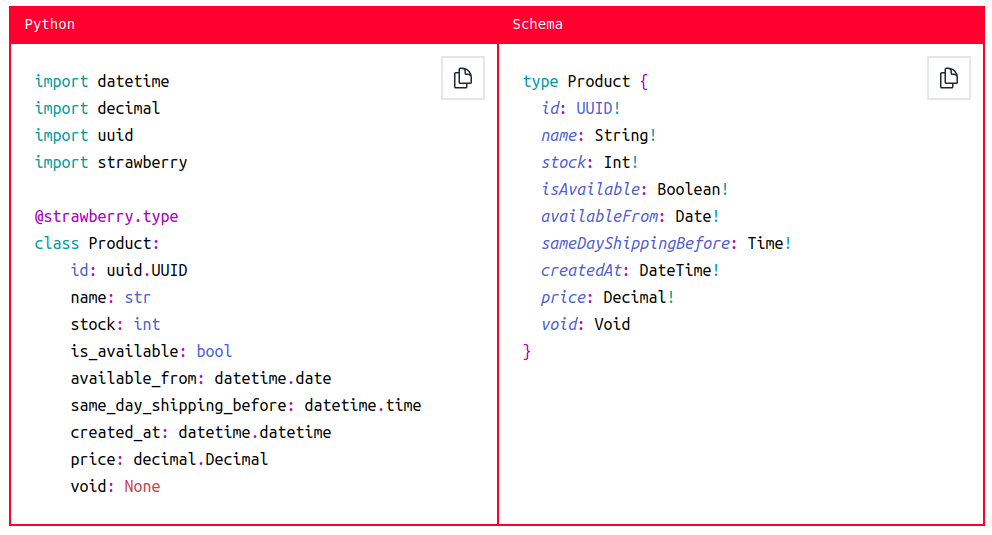
Тут можна побачити ще одну особливість GraphQL. Ця мова суворо типізована – для кожного об’єкта у схемі повинен бути заданий тип будь-якого атрибута. Ці типи будуть видимі всім, хто має схему.
...
type Mutation {
create_author(input_schema: AuthorAdd!): AuthorAddResponse!
delete_author(author_id: Int!): AuthorNotFound
create_book(input_schema: BookAddInput!): BookAddResponse!
delete_book(book_id: Int!): BookNotFound
}
type Query {
authors: [Author!]!
author(author_id: Int!): AuthorGetResponse!
books: [Book!]!
book(book_id: Int!): BookGetResponse!
}
...
Схема досить детальна. У ній зібрані всі типи, методи, запити, які можна використовувати. Якщо передати файл фронтенд-розробнику, йому навіть не потрібно буде підіймати ваші сервіси, навіть відкривати Swagger.
Серед фронтенд-інструментів також є різні бібліотеки та розширення, які вміють працювати з цією схемою і підказувати все необхідне до найдрібніших деталей. Будь-який фронтенд-розробник подякує вам за це.
Strawberry гарний сам по собі, але його можна зробити кращим. А для цього – прикрутити його до певного популярного фреймворку. Strawberry може працювати із, зокрема, Django і Flask, але я обрав FastAPI. Потрібно увімкнути роутер із префіксом, який розглянуто на ілюстрації вище. Ім’я може бути будь-яке, але знов-таки найчастіше задають /graphql.
def create_app() -> FastAPI:
_app = FastAPI(title='LectureAPI', version='0.1.0')
graphql_router = GraphQLRouter(schema=create_graphql_schema(), context_getter=_get_context)
_app.include_router(graphql_router, prefix='/graphql')
return _appДалі треба прописати схему GraphQL, що була розглянута вище. Вона ділиться на queries та mutations. Перші – це все, що стосується отримання даних. Другі – це зміни даних: додавання, видалення, оновлення. У результаті задаємо квері й мутації та об’єднуємо схему, яка представлена нижче.
def create_graphql_schema() -> strawberry.Schema:
queries = (AuthorsQuery, BooksQuery)
mutations = (AuthorsMutation, BooksMutation)
return strawberry.Schema(
query=merge_types('Query', queries),
mutation=merge_types('Mutation', mutations),
config=StrawberryConfig(auto_camel_case=False),
)Результат цього – одна велика схема з мутаціями та квері, яку ми обговорювали вище.
Використання FastAPI дає ще один плюс. Окрім GraphQL, ми зберігаємо можливість працювати із REST API. Це може бути корисним у деяких випадках. Наприклад, у вас є платіжна система, яка відправляє вебхук про оплату і найчастіше не вміє працювати з GraphQL. Таку проблему нерідко вирішують підняттям додаткових сервісів, які конвертують REST-запит у GraphQL-запит і відправляють на сервер. Але завдяки FastAPI можна просто додати REST-ендпоінт.
І тут варто згадати важливий нюанс. Погодьтеся, було б незручно отримати схеми, а далі робити щось на власний розсуд, писати запити вручну, звіряючи їх зі схемою. Тому для комфортної роботи існує безліч різних GraphQL-клієнтів. Strawberry надає GraphiQL: зручний, із приємним інтерфейсом, він буквально одразу пропонує вам щось зробити. Щоб користуватися ним, достатньо запустити застосунок і відкрити створений ендпоінт /graphql у браузері.
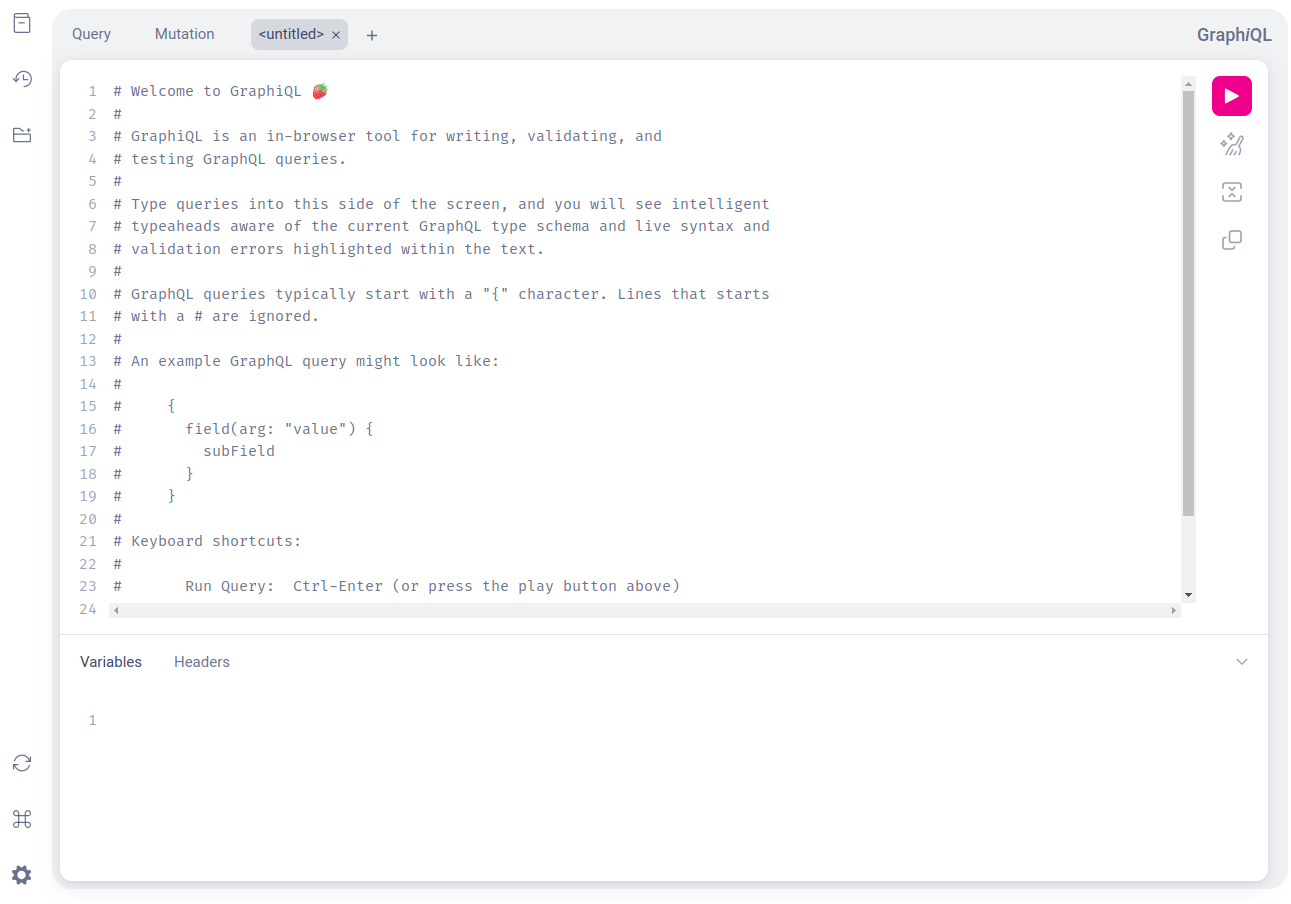
Клієнт також завантажує детальну документацію про всі наші типи, квері, мутації, методи тощо.
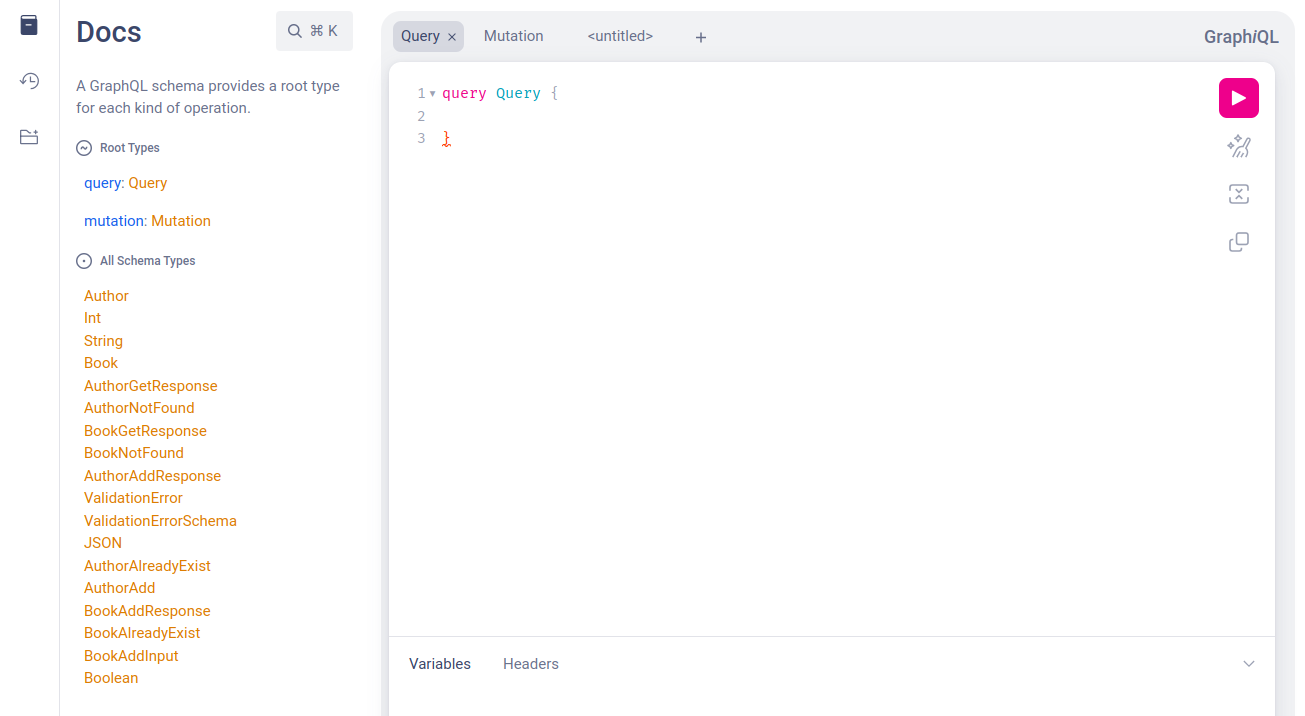
Як працювати з query у GraphQL
Перш ніж розглядати написання query, оцінимо, як це виглядає у Python-коді. query тут виглядає так:
@strawberry.type
class AuthorsQuery:
@strawberry.field
async def authors(self, info: Info) -> list[AuthorType]:
service = AuthorService(settings=info.context['settings'])
return await service.get_authors()Оскільки GraphQL є типізованою мовою, потрібно прописати тип того, що ми віддаємо. Те ж саме буде конвертоване в GraphQL-тип. Strawberry базується на дата-класах, тому синтаксис для типів буде дуже схожим, але з деякими поліпшеннями та розширеннями. Його також можна перетворити на словник, як звичайний дата-клас, використовувати default factory тощо. Що стосується доповнень, то @strawberry.type(name='Author') – це аліас: те, як тип бачить клієнт у схемі.
@strawberry.type(name='Author')
class AuthorType:
id: int
name: str
@strawberry.field
async def books(self, info: Info) -> list[Annotated['BookType', strawberry.lazy('app.graphql.books.types')]]:
...
Приємним доповненням є механізм дата-лоадерів. Він дає змогу задати логіку того, як це поле буде прораховане або отримане. Якщо у вказане поле не вставити значення явно, Strawberry зможе отримати його самостійно.
@strawberry.type(name='Author')
class AuthorType:
id: int
name: str
@strawberry.field
async def books(self, info: Info) -> list[Annotated['BookType', strawberry.lazy('app.graphql.books.types')]]:
from app.graphql.books.service import BookService
service = BookService(settings=info.context['settings'])
return await service.get_books_by_author_id(self.id)Коли в результаті у клієнті ми пропишемо квері з викликом методу authors і лише його id та ім’я (адже часто зовсім не обов’язково запитувати всю інформацію), то в результаті отримаємо тільки те, що й запитували.

За потреби можна додати поля і запросити всі книжки авторів.
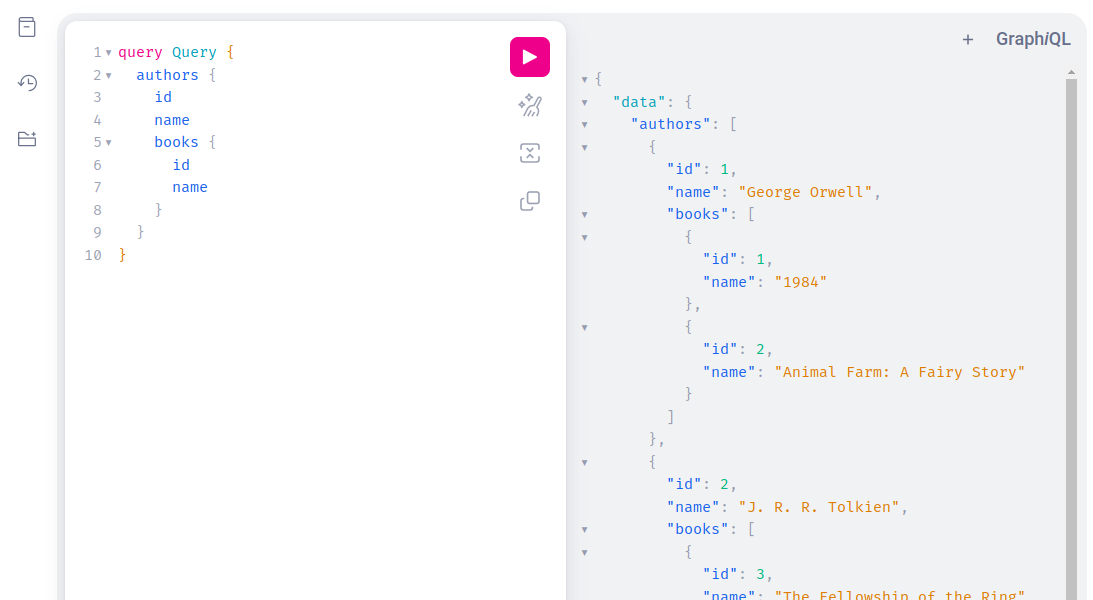
На відміну від REST GraphQL не обмежує єдиним запитом. У випадку REST в одному запиті можна взяти лише одну сутність: автора, перелік книг тощо. У GraphQL в одному запиті групується скільки завгодно непов’язаних одна з одною сутностей.
Коли це може стати у пригоді? Припустимо, у вас завантажується сторінка, і потрібно відразу отримати декілька різних сутностей. Усе це можна зробити одним GraphQL-запитом.
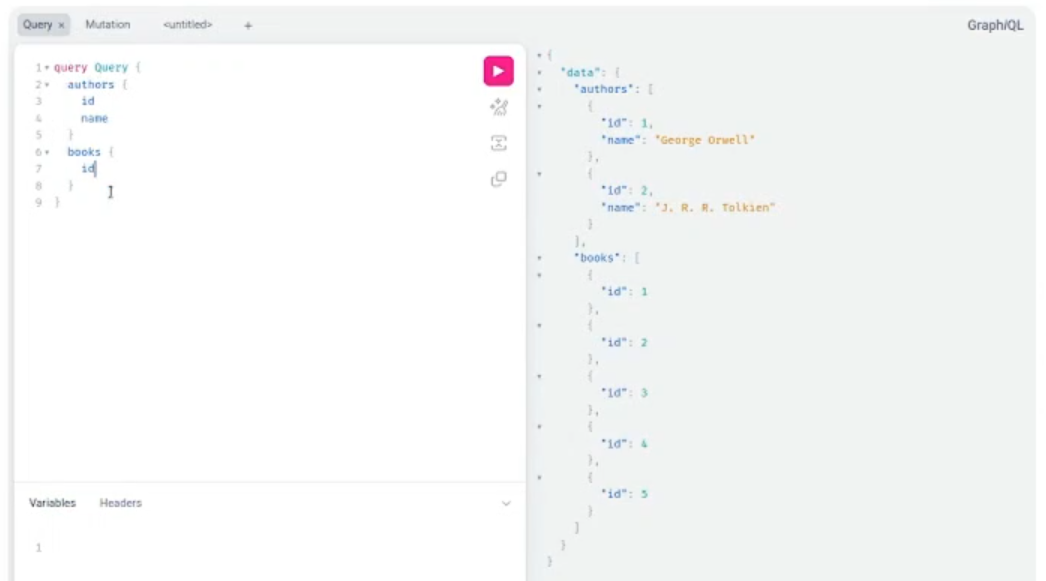
Але тут є кілька проблем. GraphQL працює поверх HTTP, але він не заглиблюється у механізми роботи з ним. Існує тільки POST-запит та відповідь на все зі статус-кодом 200. Максимум – відповідь 500, якщо серверу зовсім погано.
Якщо ви надішлете запит на отримання автора за ID і він не буде знайдений, або надішлете запит на отримання всіх книжок, то зазвичай повинні отримати статус-коди 404 та 200 відповідно. Але GraphQL обійдеться без статус-кодів. Як же без них зрозуміти, що щось пішло не так? На цей випадок GraphQL має альтернативу. Розглянемо приклад.
Нижче ви бачите звичайний get-запит, що шукає автора по ID. Тут може бути цілком доречною помилка, що автора не знайдено.
@strawberry.type
class AuthorsQuery:
@strawberry.field
async def authors(self, info: Info) -> list[AuthorType]:
...
@strawberry.field
async def author(self, author_id: int, info: Info) -> AuthorGetResponse:
service = AuthorService(settings=info.context['settings'])
try:
author = await service.get_author_by_id(author_id)
except NotFoundError as e:
return AuthorNotFoundResponse(message=str(e))
return authorНа допомогу приходять ті самі типи. Ми можемо створити новий тип для відповіді на запит, у який включити можливі помилки. Це може бути будь-яка інформація, яка дозволить зрозуміти, що сталося. У нашому випадку додамо до відповіді на запит інформації автора можливу помилку про те, що він не знайдений. А далі за допомогою юніона створимо AuthorGetResponse.
@strawberry.type(name='AuthorNotFound')
class AuthorNotFoundResponse:
message: str = 'Requested Author not found'
AuthorGetResponse = strawberry.union('AuthorGetResponse', (AuthorType, AuthorNotFoundResponse))У підсумку результат відповіді на запит для наявного автора залишиться незмінним, а квері матиме такий вигляд.
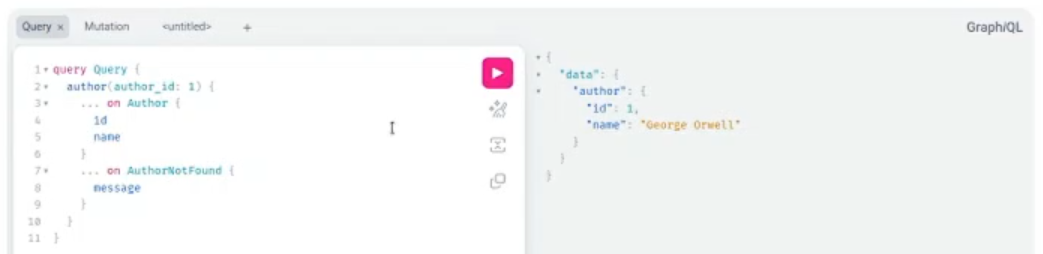
Якщо дати запит на відсутнього автора з ID 99, то нічого й не знайдеться, тож отримаємо відповідний response.
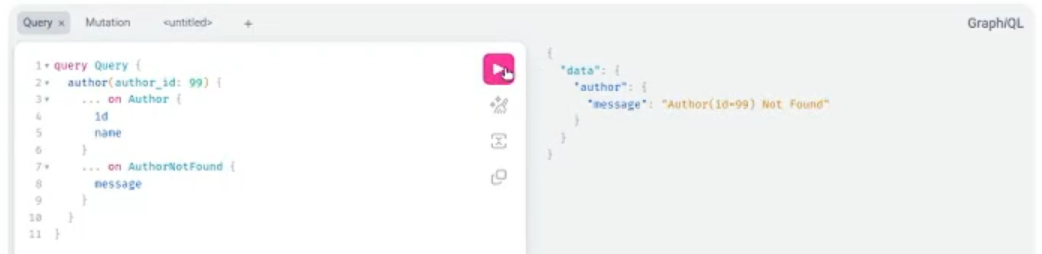
На перший погляд, це все додає труднощів. Ми змушені думати про об’єкти та створювати додаткові структури замість того, аби просто повернути статус-код, з яким вміє працювати клієнт. Та GraphQL гарно інтегрується у роботу з клієнтом. Майже будь-яка фронтендівська бібліотека вміє навішувати певні дії на помилки на кшталт «Автор не знайдений» чи «Автор не існує».
Тобто на фронтенді не потрібно буде перевіряти статус-коди, писати безліч if блоків і роздувати логіку. Бібліотека сама розбереться, що вона отримала помилку «Автор не знайдений», і викличе відповідну обробку цієї події. Це дійсно зручно й інформативно.
Як працювати з mutation у GraphQL
Отримувати дані – це добре, але хотілося б вміти їх змінювати. Тому, окрім квері, важливо розібратися з мутаціями.
Зауважу: у моїх прикладах як бази даних використовуються прості JSON-файли. Але все це буде так само працювати зі SQL, NoSQL і сторонніми сервісами.
Почнемо з поняття extension. Простіше кажучи, це як middleware на всю схему. У Strawberry безліч таких екстеншенів. Наприклад, можна використовувати вбудовані обмеження максимального числа рекурсії у 3, щоб користувач не писав запити із великим рівнем вкладеності.
def create_graphql_schema() -> strawberry.Schema:
extensions = (
QueryDepthLimiter(max_depth=3),
ValidationCache(maxsize=256),
ParserCache(maxsize=256),
# ApolloTracingExtension, # Enable performance tracing
# MaskErrors(), # Hide error description, like "Debug=False"
)
queries = (AuthorsQuery, BooksQuery)
mutations = (AuthorsMutation, BooksMutation)
return strawberry.Schema(
query=merge_types('Query', queries),
mutation=merge_types('Mutation', mutations),
extensions=extensions,
config=StrawberryConfig(auto_camel_case=False),
)Можемо використати розширення QueryDepthLimiter. У такому випадку система видасть помилку, якщо квері буде занадто глибокою. Як ми бачимо нижче, GraphQL не виключає можливість помилок у квері, тож такі обмеження можуть бути корисними.
Або, наприклад, якщо у вас використовується деревоподібна структура з parent і child, то корисно пройти вглиб до якогось елемента, а також мати ліміти на глибину такого проходу. Загалом GraphQL чудово працює із деревоподібними структурами.
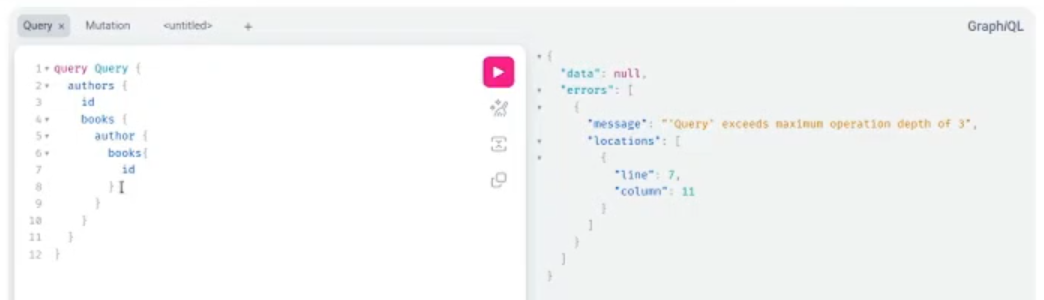
Також Strawberry дає змогу писати будь-які кастомні extensions. API досить простий, тому можна для всього необхідного написати екстеншн як на всю програму, так і безпосередньо на якийсь метод. Наприклад, я до create_author додав Pydantic-валідацію.
@strawberry.type
class AuthorsMutation:
@strawberry.mutation(extensions=[PydanticValidationExtension(AuthorCreate)])
async def create_author(self, input_schema: AuthorAddInput, info: Info) -> AuthorAddResponse:
service = AuthorService(settings=info.context['settings'])
try:
author = await service.create_author(name=input_schema.name)
except AlreadyExistError as e:
return AuthorAlreadyExistResponse(message=str(e))
return authorЦей extension завантажує модель і при помилці валідації видає відповідний error response. Так ми позбавимося ручної валідації у кожному методі, куди додамо наш extension. Натомість достатньо навісити потрібний нам extension.
Нижче показано досить «сирий» підхід. Напевно, не слід застосовувати його у продакшн-проєктах, але сама суть тут має бути зрозумілою:
class PydanticValidationExtension(FieldExtension):
def __init__(self, model: Type[BaseModel]):
self.model = model
async def resolve_async(self, next_: AsyncExtensionResolver, source: Any, info: Info, **kwargs):
if 'input_schema' in kwargs:
try:
self.model(**strawberry.asdict(kwargs['input_schema']))
except ValidationError as e:
return ValidationErrorResponse(
message='Validation Error',
errors=[
ValidationErrorSchema(
message=e['msg'], location=list(e['loc']), type=e['type'], ctx=e.get('ctx')
)
for e in e.errors()
]
)
return await next_(source, info, **kwargs)Переходимо до мутацій. Створимо якогось автора. Важливо, що клієнт GraphiQL постійно видає підказки під кожне слово, а ліворуч зібрана документація з описами, що вона очікує, які типи даних тощо. Все це помітно полегшує роботу із GraphQL.
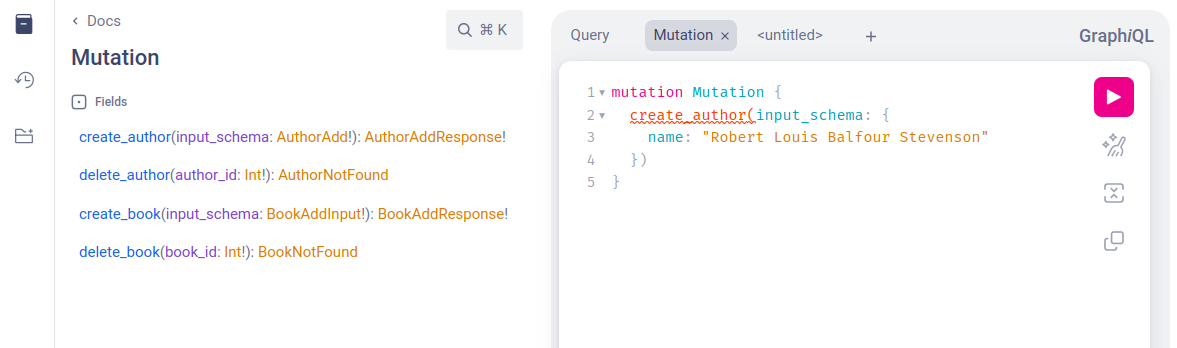
Але GraphQL одразу видає попередження: потрібно обов’язково щось повернути. Як мінімум, це буде ID.
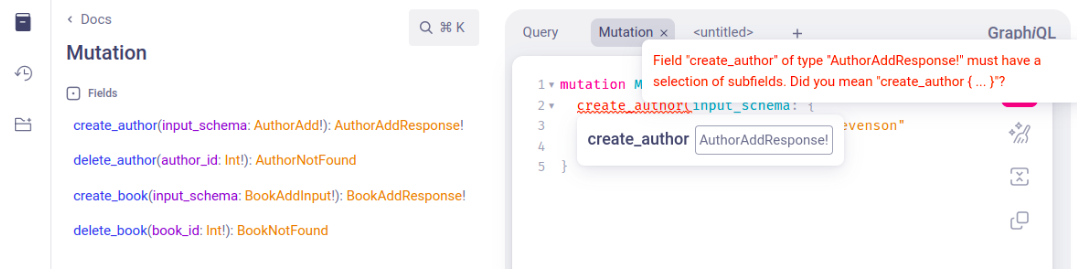
Не забуваємо про можливість помилок. Тому на успішну відповідь поставимо повернення ID, а припустимо, на AuthorAlreadyExist повертатиметься message.
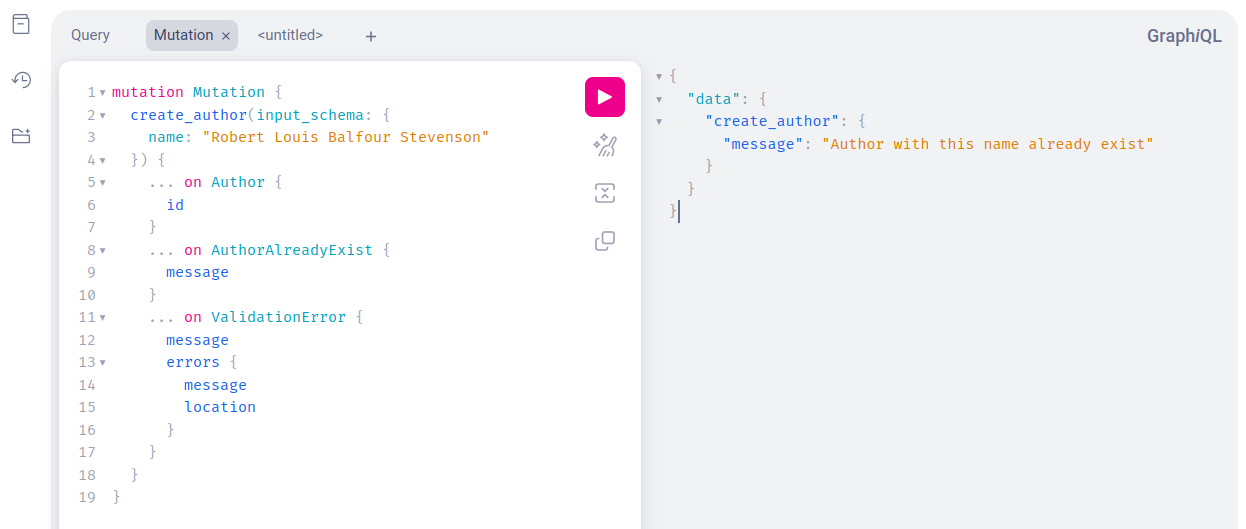
Якщо написати щось зовсім неадекватне, то наш PydanticValidationExtension явно вкаже, що саме ви робите некоректно.

Грубо кажучи, все це є вхідною точкою у нашу систему, яка не так вже й відрізняється від звичних REST-ендпоінтів. Просто тут дещо інша логіка вирішення тих чи інших проблем. Насправді практично будь-яку REST API можна реалізувати й на GraphQL. За умови правильної архітектури системи можна без проблем перейти на GraphQL, не змінюючи написаної логіки.
Як тестувати GraphQL
Нагадаю, що я БД у своїх прикладах я використовую JSON-файли. Їх я очищую перед кожним тест-кейсом, емулюючи поведінку ролбеку транзакцій.
TEST_DB = os.path.join(pathlib.Path(os.path.dirname(os.path.realpath(__file__))), 'db')
@pytest.fixture(scope='session')
async def app() -> FastAPI:
from app.main import create_app
_app = create_app()
yield _app
@pytest.fixture(scope='session')
async def client(app: FastAPI) -> AsyncClient:
async with AsyncClient(app=app, base_url=TEST_HOST) as client:
yield client
class TestBaseDBClass:
"""Provides Test Class with loaded database fixture"""
@pytest.fixture(autouse=True, scope='function')
def _provide_db(self):
"""Provides an empty database for all tests in class"""
all_db_files = os.listdir(TEST_DB)
for file_path in all_db_files:
open(os.path.join(TEST_DB, file_path), 'w').close()
class TestBaseClientClass:
"""Provides Test Class with loaded client fixture"""
@pytest.fixture(autouse=True)
def _provide_client(self, client: AsyncClient):
"""Provides client for all tests in class"""
self.client = client
class TestBaseClientDBClass(TestBaseClientClass, TestBaseDBClass):
"""Provides Test Class with loaded database and client fixture"""Пропоную розібрати тест на отримання списку авторів. У цьому випадку можна виявити єдиний неприємний момент: потрібно вручну прописати query як строку. Тобто жодних підказок або помилок синтаксису ми тут не побачимо.
class TestAuthorList(TestBaseClientDBClass):
QUERY = """
query TestQuery {
authors {
id
}
}
"""
async def test_list(self):
...
Далі потрібно прокинути в тіло запиту QUERY, використовуючи тестовий клієнт. Адже, як було зазначено вище, GraphQL працює поверх HTTP, тому не потрібно вигадувати нічого нового.
class TestAuthorList(TestBaseClientDBClass):
QUERY = """
query TestQuery {
authors {
id
}
}
"""
async def test_get_empty(self):
response = await self.client.post('/graphql', json={'query': self.QUERY})
response_authors = response.json()['data']['authors']
assert response_authors == []
async def test_list(self):
author1, author2 = await create_test_author(), await create_test_author()
response = await self.client.post('/graphql', json={'query': self.QUERY})
response_authors = response.json()['data']['authors']
assert response_authors == [
{'id': author1.id},
{'id': author2.id},
]
У результаті все працює, як слід. І навіть більше: ми не втрачаємо дебагер. Тобто можна продебажити будь-який код, залізти в будь-який сервіс і подивитися, що пішло не так.

До речі, схема підтримує параметри. Якщо вам потрібно отримати конкретного автора і ви хочете підставляти значення динамічно, потрібно просто прописати будь-який валідний GraphQL-тип. При цьому він може бути як найпростішим, на кшталт Integer, так і самописним, як Author.
class TestAuthorGet(TestBaseClientDBClass):
QUERY = """
query TestQuery($author_id: Int!) {
author(author_id: $author_id) {
... on Author {
id
name
books {
id
author_id
name
}
}
... on AuthorNotFound {
message
}
}
}
"""
Тобто у вас можуть бути всі типи, представлені у схемі:
Для того, щоб підставити необхідні змінні, використаємо атрибут variables.
class TestAuthorGet(TestBaseClientDBClass):
QUERY = """
query TestQuery($author_id: Int!) {
*skiped*
}
"""
async def test_get(self):
author = await create_test_author()
response = await self.client.post(
'/graphql', json={'query': self.QUERY, 'variables': {'author_id': author.id}}
)
response_author = response.json()['data']['author']
assert response_author['id'] == author.id
assert response_author['name'] == author.name
Нарешті можна тестувати, як усе працює. На статус-код перевірки немає, тому що GraphQL не працює з ним. Але оскільки все працює на базі HTTP, то Strawberry за необхідності дає змогу поставити статус-код.
Однак майте на увазі: в межах одного Query може бути кілька запитів. Тож вам доведеться самим вирішувати, що робити, якщо один із них віддасть 200, а інший – 404.
Із мутаціями ситуація аналогічна. Тільки замість query з’являється mutation.
class TestAuthorCreate(TestBaseClientDBClass):
MUTATION = """
mutation TestMutation($name: String!) {
create_author(input_schema: {name: $name}) {
... on Author {
id
name
}
... on ValidationError {
message
}
... on AuthorAlreadyExist {
message
}
}
}
"""
async def test_create(self):
author_factory = AuthorFactory()
response = await self.client.post(
'/graphql', json={'query': self.MUTATION, 'variables': {'name': author_factory.name}}
)
response_author = response.json()['data']['create_author']
assert response_author['name'] == author_factory.nameЯк бачите, тести на GraphQL особливо нічим не відрізняються від звичних для нас API-тестiв.
Якщо хочете докладніше вивчити цей приклад, розібратися в описаних вище деталях і власноруч запустити окремі кроки, то переходьте на сторінку цього проєкту на GitHub.
Переваги та недоліки GraphQL
Щоб узагальнити цю тему, пройдемося по основним, на мій погляд, перевагам та недолікам GraphQL.
Серед позитивних ознак можна виокремити такі:
- Чудово підходить для мікросервісів. GraphQL надає зручну уніфіковану точку доступу з єдиним форматом для всієї системи. Це приховує весь масштаб і складність системи.
- Простота використання. GraphQL отримує дані на основі одного запиту, без необхідності зосереджуватися на окремих endpoints, потрібних для збору даних. Користувач може запросити всі необхідні дані лише за допомогою одного виклику. Тут немає статус-кодів, тож вам не потрібно розбиратися, де і коли використовувати GET, PUT, PATCH, POST тощо. Вам треба лише писати query, щоб отримувати від системи все необхідне.
- Точність. Завдяки GraphQL у вас не буде проблем із недостатньою чи надмірною вибіркою, яка була розглянута на самому початку.
- Валідація самого себе і типізація. GraphQL поставляється з валідацією і перевіркою типу у стандартній комплектації. Програми можуть запитувати тільки те, що можливо, у відповідному форматі.
Що стосується недоліків GraphQL, то я б виокремив такі:
- Низька швидкість. GraphQL може бути повільним у деяких випадках. Клієнт може прописати дуже важкі запити, які за будь-якого ступеня оптимізації будуть виконуватися тривалий період. Наприклад, так може бути при запиті занадто великої кількості полів одночасно.
- Проблеми вебкешингу. Оскільки GraphQL, працюючи за POST-методом, не використовує методи кешування на рівні HTTP, зберігання вмісту запиту відбувається на самому сервері. Наприклад, використання CDN, які працюють із GET-методом, стає неможливим у більшості випадків або вимагає дуже багато sidework.
- Складність входу. GraphQL простий, але тільки після того, як ви розберетеся з концепцією. А на старті багато що може викликати складності та запитання. Якісь типи, схеми, помилки та команди, що робити, – це все не дуже інтуїтивно зрозуміло. Тому може бути потрібен час, щоб вивчити всі механізми цієї мови запитів.
- Неочевидні переваги при HTTP/2. При взаємодії систем за протоколом HTTP/2 в межах єдиного з’єднання виконується мультиплексування запитів і відповідей з використанням нового бінарного рівня. Завдяки цьому HTTP/2 ефективно підтримує обробку дуже багатьох запитів. А це робить перевагу GraphQL у вигляді «одного запиту, що розв’язує всі проблеми», менш вагомою. Тобто REST знову стає привабливішим рішенням.
Підписуйтеся на ProIT у Telegram, щоб не пропустити жодну публікацію!