
У цьому матеріалі я – Роман Чуйко, Oracle Developer у компанії Telesens, хочу розповісти про актуальні проблеми, з якими можуть стикатися девелопери при видаленні старих даних із таких баз даних, як Oracle.
Протягом усього процесу розробки, стикаючись із труднощами, які доводилося вирішувати самому або мозговим штурмом команди чи просто перебираючи інформацію в інтернеті, я сформував чек-ліст цих проблем та описав деякі способи їх вирішення.
Сповіщення
Неінформативні сповіщення
При роботі застосунок повертає ті чи інші сповіщення, які висвітлюють ті події, які в ньому сталися. Переважна більшість сповіщень прості й несуть тільки загальну інформацію про суть події. Буває важко передбачити причину можливої події, щоб її детально описати й дати якісь рекомендації. Тому при виникненні таких подій доводиться по факту виникнення доповнювати опис або навіть розділяти одну подію на декілька із різними порадами.

На верхній частині скріншота ми бачимо сповіщення, яке не дає достатньо інформації про подію, яка відбудеться. Ми не розуміємо добре це, чи ні.
На нижній частині ми бачимо, що усе гаразд, обробка вже була завершена і навіть можемо підставити в застосунку значення періоду, за який ця подія відбулася
Особливу увагу треба звертати на сповіщення із зовнішніх модулів, таких як, наприклад, Perl-скрипти. При виникненні помилки вони можуть повернути у викликаючий модуль, тільки код завершення роботи скрипта, без додаткових параметрів. Тут, по можливості, треба записати подію в базу, а Perl-скриптом видавати помилки у виняткових випадках, коли немає коннекту із базою.
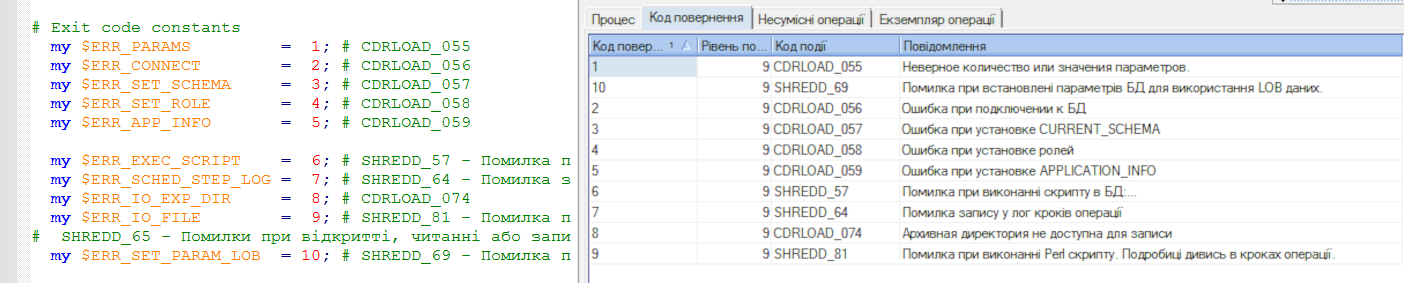
З лівого боку скріншота ми бачимо об’явлені коди повернення у скрипті, а справа до цих кодів прив’язані сповіщення основного застосунку
Також слід мати можливість перехоплювати сповіщення/помилки, які генерує скрипт при виконанні, й записувати їх у лог системи/застосунку на клієнті.
Не вистачає сповіщень
При роботі застосунку (особливо тих процесів, які працюють у фоновому режимі) трапляються випадки, коли процеси завершуються коректно, але з логу незрозуміло, що цей процес робив (чи не робив) і чому.

У верхньому гриді ми бачимо, що процес відпрацював без помилок, але на вкладці «Крок» немає жодного запису про роботу процесу. Запис у нижній вкладці «Крок» дає нам зрозуміти, що процес нічого не робив через те, що дані вже були оброблені!
Цей момент дуже важливий для розуміння того, що відбувалося в цей час. Загалом необхідне логування. Його кількість і місця формування сповіщень треба закладати на етапі проєктування.
Також треба розуміти, що мала кількість записів у лог кроків може бути недостатньо інформативною, а у великій кількості буде важко знайти важливу інформацію.
Потрібна золота середина між кількістю й інформативністю і це здебільшого залишається на розсуд і досвід розробника.

На цьому скріншоті зверху жовтим підкреслено 2 сповіщення на одну операцію. На нижній частині вказано, що на кожну операцію йде одне сповіщення із додатковою інформацією
Специфікація
Перед початком розробки застосунку, системи, модуля чи внесення в існуючу розробку якихось змін необхідно створити документ (специфікацію), в якому описати майбутній функціонал, вимоги (особливо замовника), якісь особливості його реалізації тощо.
Саму розробку можна поділити на деякі етапи, кроки чи модулі згідно зі специфікацією. Бажано після закінчення однієї з цих дій перечитувати специфікацію або звіряти ті її частини, реалізація яких вже завершена. Тоді зменшується ймовірність виникнення дефектів, пов’язаних із неточністю її реалізації.
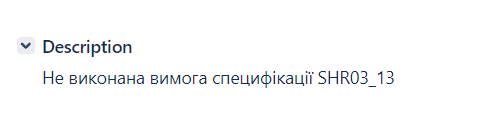
На скріншоті приводиться опис виставленого дефекту в Jira, коли неуважно читав специфікацію
Також можуть виникати непорозуміння через заплутані формулювання вимог до розробки. З цього приводу раджу намагатися переформулювати заплутані фрази, а також де це можливо розділяти на простіші й більш зрозумілі речення.

На цьому скріншоті показано переформулювання деякої частини вимоги, щоб вона була більш зрозумілою для усіх читачів, а не тільки автору наведеного тексту
Особливу увагу приділяйте даним, які часозалежні. При розробці алгоритму обробки даних можуть бути ситуації, коли дані виходять за межі оброблюваного періоду в силу наявності зв’язку з даними інших дат. На це треба звертати увагу саме у специфікації, щоб потім не отримувати дефекти із наведеним нижче описом:

Ще один нюанс, з яким ви можете зіткнутися під час розробки, – не все описане у специфікації можливо чи доречно реалізовувати в такому вигляді, як описано. Можна сказати, що треба уважніше й більш скрупульозно писати специфікацію, але ж не завжди є змога все врахувати заздалегідь. Частково в цьому допомагає досвід, який отримуєш при розробці інших модулів/систем.
Партиції
При розробці буває дуже зручно, коли декілька партиційованих таблиць мають єдине правило ділення на секції. Наприклад, партиції розділяються на однакові діапазони дат. Це зручно і для архівування даних, і для очистки, і для відновлення. Але можуть виникати проблеми з тестовим середовищем, коли відбувається розсинхронізація між партиціями таблиць.
Наприклад, у партицій різні діапазони дат. Тут рятують додаткові перевірки наявності й статусу партицій у системних таблицях, щоб не отримувати помилки, як, наприклад, таку:
ORA-02149: Specified partition does not exist
Більш специфічна проблема, з якою можна зіткнутися, це коли вказаний діапазон обробки дуже великий (таблиця розділена на секції по днях), але насправді в ньому небагато даних і немає сенсу обробляти усі партиції, які увійшли в цей діапазон. Потрібна додаткова перевірка: в яких партиціях знаходяться дані та їх треба обробляти, а які можна пропустити.

Жовтим вказаний оброблюваний діапазон дат 11.2012 і реальний діапазон даних, які в нього входять
Ручна зупинка процесу/операції
У деяких застосунках вбудована можливість зупиняти деякі операції вручну, особливо ті, що займають багато часу. Користувач може вручну припинити виконання процесу/операції в будь-який момент.
Звісно, існує загальне правило, що від моменту виставлення сигналу зупинки до моменту самої зупинки не повинно проходити більше 30 секунд (в різних організаціях можуть бути різні значення цієї константи).
Однак не завжди є можливість так швидко припинити цю операцію стандартними методами, як, наприклад, вибірка даних із бази даних складним запитом. Бажано робити скрипти вибірки даних, виконання яких займає небагато часу.
Після отримання сигналу зупинки треба прослідкувати за коректним завершенням роботи всіх модулів/скриптів, які задіяні в цьому процесі обробки даних, а не тільки в тому, де цей сигнал виявлено.
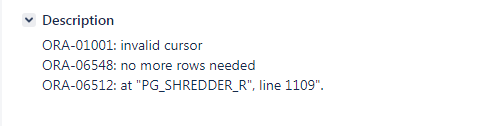
Некоректне закриття курсору при отриманні сигналу зупинки модуля
Також рекомендую зробити відповідний запис в лог. Перед цим обов’язково важливо визначитися, в якому місці (модулі/скрипті) це буде доцільним, щоб не було дублювання сповіщень, коли модулі взаємодіють між собою.

У цьому сповіщенні показано, що не той модуль обробляв сигнал зупинки обробки, тому й згенероване сповіщення не описує ситуацію, що відбулася
Відновлення обробки після збою
Дуже важливий крок розробки – це включення в нього засобів, які дозволяють продовжити обробку даних після збою, помилки або ручного завершення процесу обробки. Ця можливість повинна враховуватися на етапі проєктування, щоб органічно вписуватися у розробку.
Як варіант реалізації механізм відновлення створюється на основі журналу процесів. У нього записуються оброблені дані за період або частину періоду (для партиційованих таблиць), що дає змогу, аналізуючи лог попереднього запуску, виключити оброблені дані зі списку обробки при повторному запуску процесу.

На скріншоті ми бачимо, які об’єкти та за який період оброблені. У разі збою повторний запуск процесу вилучить із черги обробки вже оброблені дані
Також сюди можна додати механізм захисту від наступних дій, які залежать від результату проходження попередньої обробки. До прикладу, не запускати чистку даних за період, архівація якого була перервана.
Це можна реалізувати на основі журналу архівів (дивитися скріншот нижче). Водночас дуже важливо налаштувати коректну роботу кожного з цих механізмів для правильної роботи всієї системи.
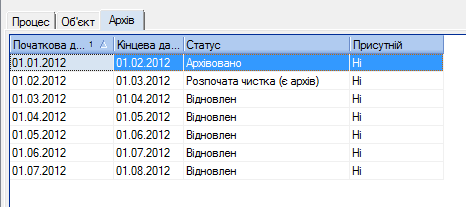
На скріншоті показано, що почався процес очистки. Якщо буде збій, то наступний процес враховуватиме це
Налаштування системи
Трапляється й таке, коли через неуважність забуваєш внести деякі налаштування для розробленого модуля чи вони не увійшли в оновлення системи.
Наприклад, коли виконується якийсь процес, то він видає повідомлення, яким для зручності присвоюється номер помилки. По цьому номеру можна і користувачу, і застосунку зрозуміти, якого ступеня важливості є ця помилка:
0 – це інформативне сповіщення;
1 – це попередження, що сталася некритична помилка, яка не впливає на подальшу роботу застосунку й так далі.
Якщо неправильно налаштувати цей рівень для якоїсь задачі/процесу, тоді після її завершення застосунок може неправильно оцінити результат (дивіться скріншот нижче).
Щоб цьому запобігти, краще внесені зміни записувати у записник/файл (чи в інше місце), оскільки не завжди вдається тримати у голові заміну якогось параметру на формі, який треба додати до патчу.
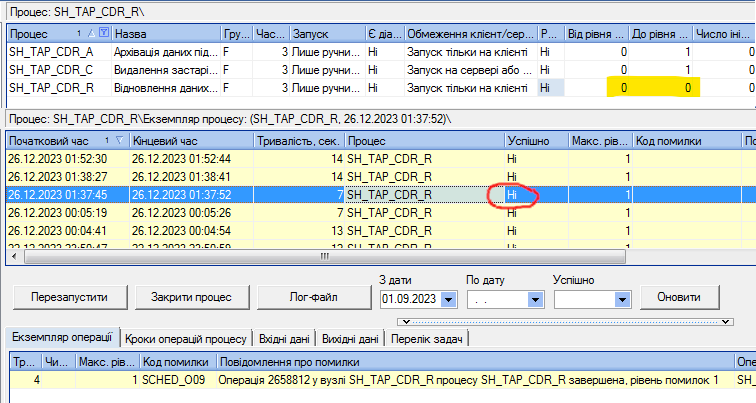
На скріншоті показано, що неправильно налаштований рівень помилки (на верхньому гріду підкреслено жовтим) призводить до некоректного позначення завершення процесу (в середньому гріду обведено червоним)
Пов’язані дані
Є неприємні випадки для архівації/відновлення, коли рядок таблиці посилається на інший рядок цієї ж таблиці. Ця рекурсія може мати кілька рівнів.
Доводиться зберігати додаткові дані й позначати їх як рекурсивні, а при подальшому відновленні не забувати правильно їх обробляти. Тут треба бути уважним із зовнішніми ключами.

На скріншоті показані пов’язані між собою рядки (ID виділені жовтим). У нижньому гріду показаний зв’язок по зовнішньому ключу (виділений жовтим)
Відладка модулів/скриптів
Важлива частина розробки – це закладати можливість отримати додаткову інформацію за необхідності. Можливість її вмикати/вимикати без додаткового втручання у код.

На скріншоті показаний приклад ручного логування, рядки жовтого кольору, коли треба розкоментувати позначені рядки й відкомпілювати модулі. Поганий варіант
Це дозволить отримувати потрібну для відладки інформації з користувацької системи, в якій виконується розроблений застосунок.
Як часткове рішення можна додати компонент перехоплення SQL-запитів. Наприклад, внизу вікно Debug Window, де показуються запити до БД.

Перехоплення SQL-запитів застосунку для подальшої відладки функціоналу
Ще одна важлива частина відладки – це можливість окремо тестувати модулі (процедури, функції й так далі), які входять у розробку.
На жаль, буває потрібно робити декілька додаткових дій у базі, щоб була можливість виконати тестування. У складних випадках доводиться копіювати частини модуля й окремо запускати на виконання.
Ця можливість закладається на етапі розробки кожного модуля/процедури/скрипта. Якщо при розробці використовуються глобальні змінні, колекції, тимчасові таблиці, тоді потрібно додавати механізм для їх заповнення тестовими даними.
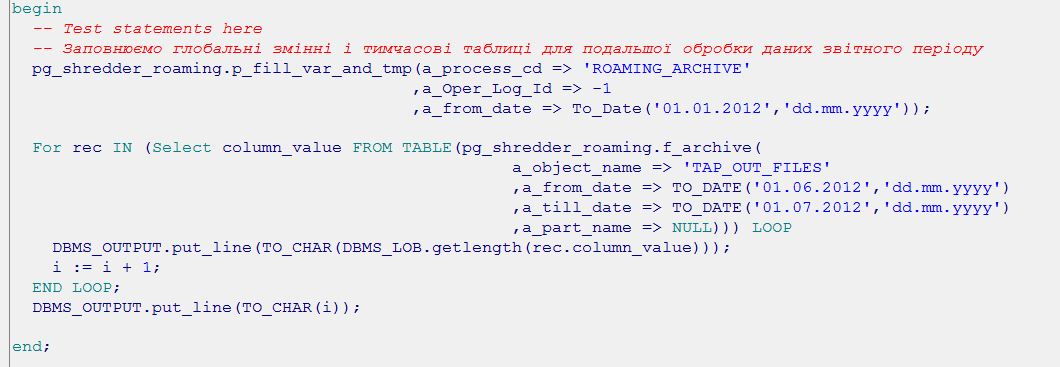
На скріншоті показано, що до початку тестування основної функції архівації “f_archive” є можливість запустити процедуру “p_fill_var_and_tmp”, яка готує для неї необхідні дані
Продуктивність
У цьому розділі наведу приклад зміни розробленого функціоналу вивантаження даних, що архівуються, на клієнтську машину для підвищення рівня продуктивності системи.
При розробці модуля вивантаження даних були використані Pipelined-функції, адже вони дозволяють робити додаткові маніпуляції з даними до їх вивантаження. Також ці функції дозволяють надсилати клієнту рядки по мірі їх готовності, а не чекаючи обробки всіх вибраних даних.
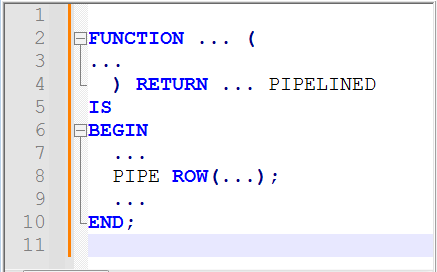
Структура PIPELINED функцій в базі Oracle
Для зменшення навантаження на клієнтську машину і спрощення обробки вивантажувальних даних на клієнті з боку бази усі стовпці запитів «склеювалися» в один текстовий стовпець із заданим форматуванням для нетекстових даних.

Приклад склеювання стовпців
При цьому виникло 2 перешкоди:
- В Oracle 11 при вивантаженні ми обмежені колонкою в 4К. Тому не виключалася ситуація, коли не всі рядки склеєних колонок деяких таблиць могли поміститися в цей розмір, якщо будуть зустрічатися повністю заповнені рядки.
- У таблицях можуть знаходиться колекція або стовпець із XML-даними, які можуть мати будь-який розмір.
Для уникнення цих перешкод краще використовувати тип CLOB для вивантаження і в подальшому завантаження даних.
Всі колонки рядка таблиць приводяться до типу CLOB, а потім склеюються в одну колонку. Далі рядок за рядком відправляються клієнту.
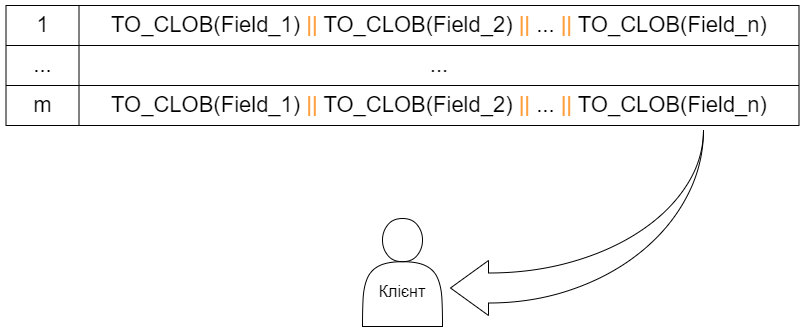
Схематично показана передача склеєних колонок клієнтському модулю застосунку
Вивантаження кожного CLOB-рядка окремо не раціонально. Оскільки тип CLOB може вміщувати багато даних, є сенс об’єднувати рядки в один великий блок даних і надсилати його клієнту.
Для цього можна використати проміжну змінну типу CLOB, в яку рядок за рядком додаються дані, а потім вміст цієї змінної надсилається на клієнта.
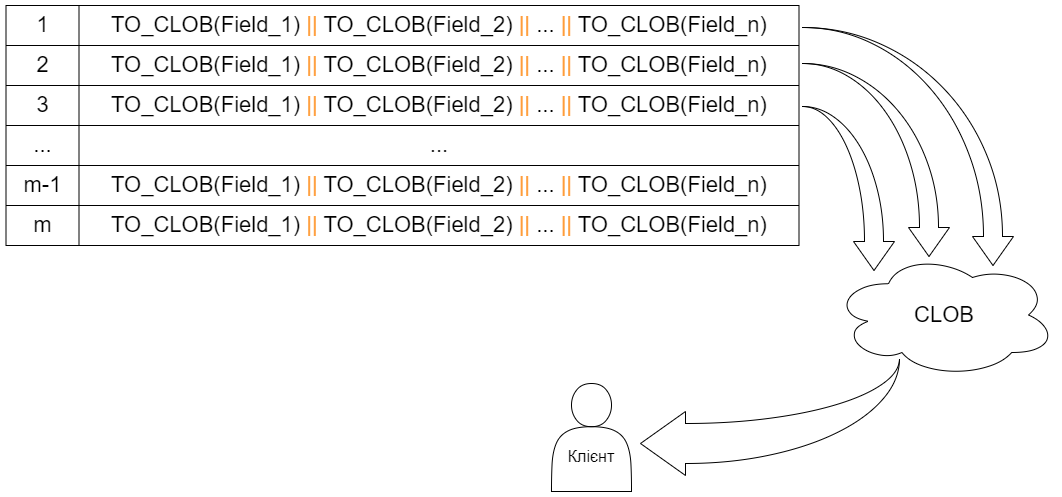
Об’єднання декількох CLOB-рядків в один CLOB, який і відправляється клієнтському модулю
Щоб зменшити використання ресурсів сервера, можна обмежити розмір CLOB-змінної й вибрані дані надсилати на клієнта порціями, які в подальшому з’єднувати на клієнті в один файл.
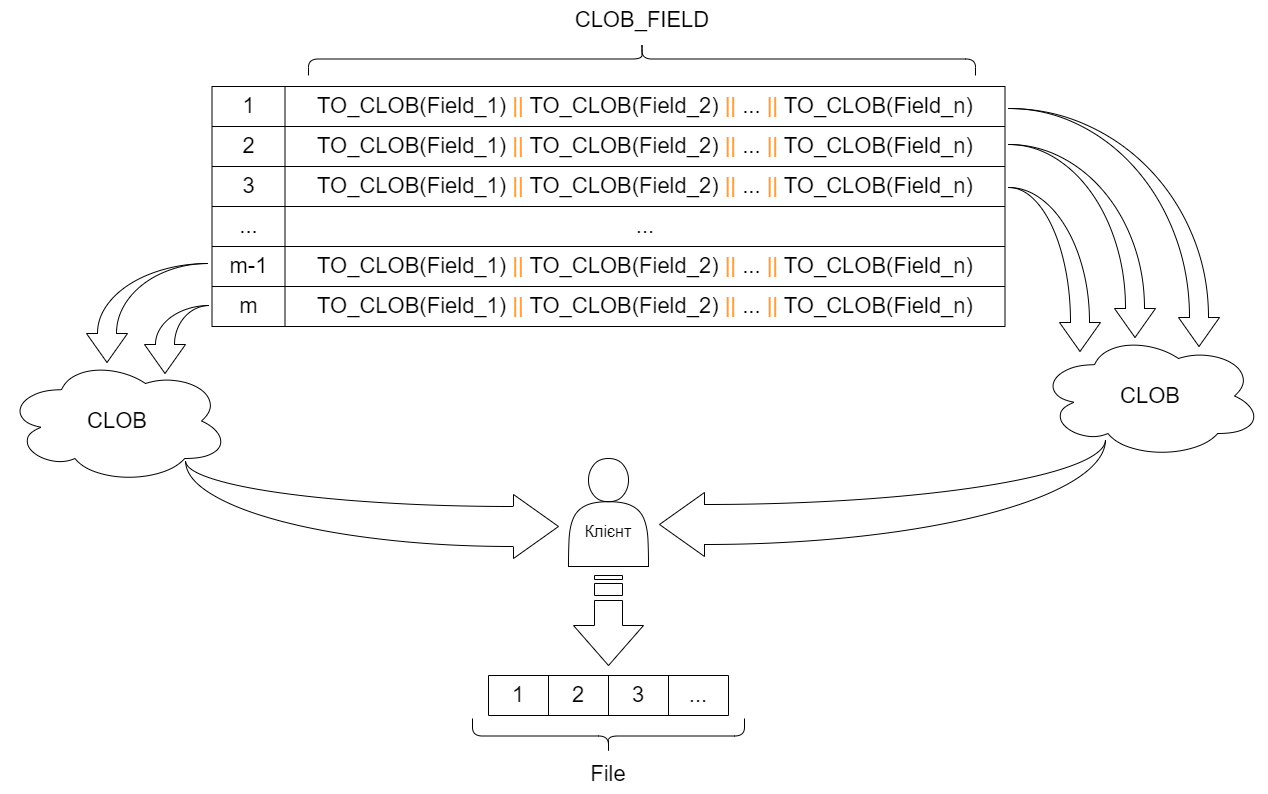
Показано надсилання даних порціями й кожну порцію дописувати в цільовий файл
Перетворення колонок в тип CLOB із подальшим їх об’єднанням в одну колонку може призвести до зниження продуктивність всієї обробки, особливо при використанні старих версій Oracle.
Для вирішення цієї проблеми в запиті всі колонки можна перевести в текст, а колекції, XML-дані й CLOB – у тип CLOB. Усі колонки окремо додаються до CLOB-змінної, і так рядок за рядком.
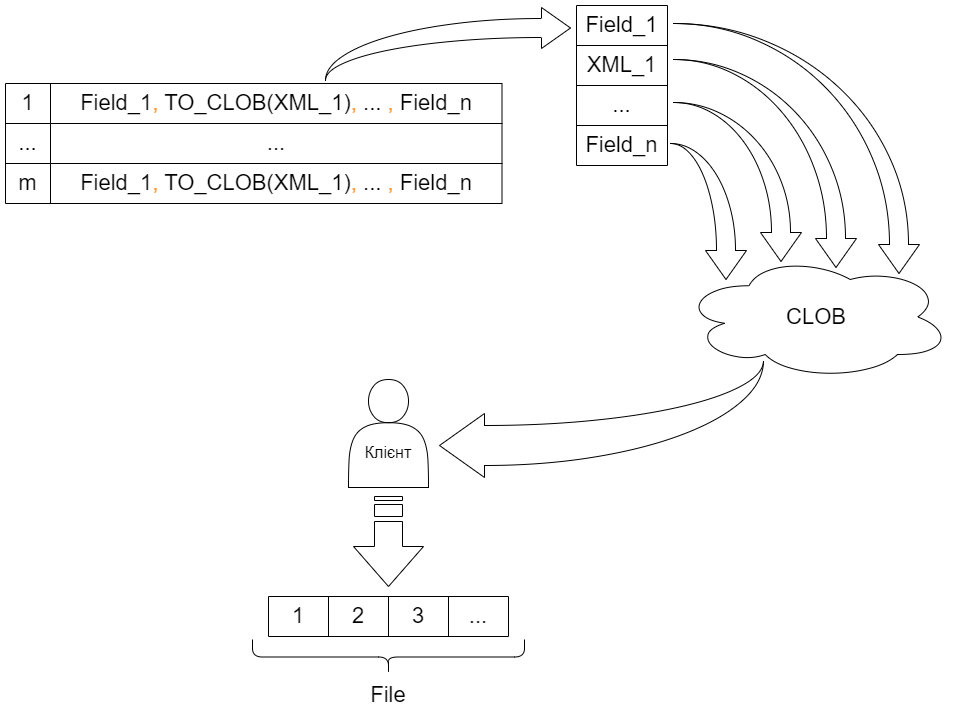
Показано, що тільки колонки XML і колекції перетворюються в CLOB для подальшого об’єднання й передачі клієнтському модулю
Обробка кожної колонки в кожному рядку окремо (особливо коли колонок в таблиці дуже багато) може займати багато часу.
Рішення полягає в об’єднанні декількох колонок в одну там, де це можливо. На практиці в таблицях небагато колонок, які мають складні формати по типу колекції чи XML, тому цей спосіб добре працює.
Винятками можуть бути таблиці, які створені як додаток до основної таблиці. В них виносять поля зі складною структурою, і тоді потрібен індивідуальний підхід для обробки цих таблиць.
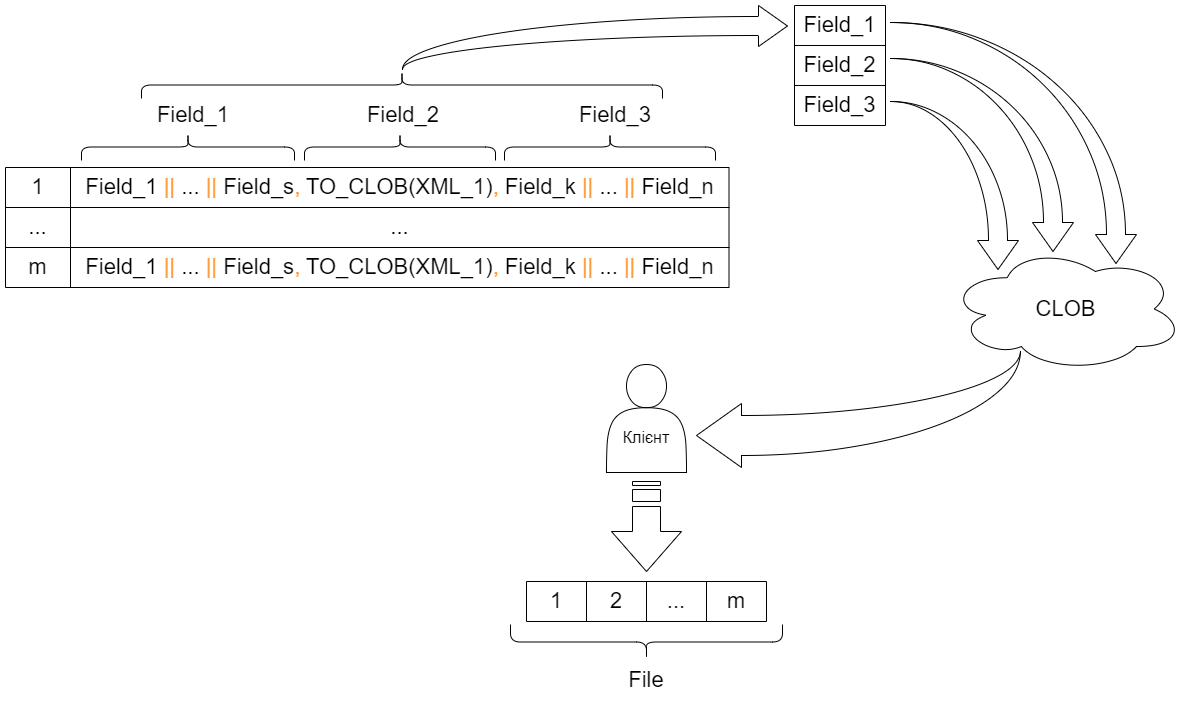
На скріншоті показано, як за допомогою склеювання полів простих типів даних можна зменшити подальшу обробку даних для передачі клієнтському модулю
Сподіваюся, що мій досвід стане у пригоді тим, хто працює чи працюватиме з Oracle!
Підписуйтеся на ProIT у Telegram, щоб не пропустити жодної публікації!